
The Code Tsunami
What is it? And what can we do about it?


Last time, I talked about how I was feeling a little befuddled.
You know that feeling when you’re solving a jigsaw puzzle. You’ve managed to find most of the edges, got a few piles of pieces that are obviously related to each other, that kinda thing. Even though it’s still unfinished, you have a much better idea what you’re doing.
That’s where I’m at.
This post is about what my “edges” and “piles” look like.
Let me start at the end
Let me explain what the future looks like, for me, as best as I can see it.
In this AI-enabled era, I’m still focused on testing and quality. I’m still concerned with surfacing and managing risk. Helping people amplify their awesomeness is still on the agenda. My testing philosophy hasn’t changed foundationally speaking i.e. the principles remain the same.
But what the work looks like is very different. How it manifests itself is very different. The way I achieve my goals and reach my objectives is very different.
Less information provider. More creator of the decision infrastructure. In the before times, I would provide information to people with authority to ship. Now the work becomes shaping and designing the mechanisms.
Less bug detection. Even more helping the team achieve shippable quality. Changing the focus of the team to incorporate the whole delivery system and not “just” bug detection was already a thing. But now the “team” includes non-humans who also work autonomously, and these “teammates” hallucinate, drift, and aren’t renowned for saying “I don’t know” or behaving cautiously when things are unclear.
Still co-creating solutions. More building. Coaching and leadership is still a thing. What’s different is the expectation to build tools to facilitate and codify that work. That requires an identity shift where I’m a little more willing to share my opinion, and also build tools/artefacts that enable others to make decisions.
Focus on delivering value by understanding the problems and goals of the people you’re trying to serve. That’s probably the one thing that remains largely unchanged.
Let me unpack what I think that means, practically speaking.
What’s going on out there?
There are things that I’ve noticed personally and things I’ve learned by doing a little poking around the interweb.
Things I’ve noticed
Do we know what we’re doing?
Before we can use these tools, we need to understand what we’re trying to get done.
Which is where Task Analysis comes in.
In the book “Task Analysis Methods for Instructional Design”, the authors define task analysis as:
…a process of analyzing and articulating the kind of learning that you expect the learners to know how to perform.
Or put it another way, task analysis is the process of breaking down and describing work clearly enough that someone, or something, else could perform it.
I think task analysis is a skill in itself and one that doesn’t get much deliberate practice (if any).
The tsunami of code is real

This is the most glaring one.
Everyone and their mama is using coding assistants. It doesn’t matter what flavour (Claude Code, Codex, Co-pilot, Cursor, Juni, whatever), they’re using them. And volume of output from developers is going up, fast.
Some of the code is being written entirely by AI. If you thought humans + AI generate a lot of output, you should see what agents can do with proper (and improper!) direction, access to tools, and seemingly unlimited tokens.
The systems we're working with aren't deterministic. Compare and contrast.
In the deterministic before times, when I ask, "Are you ok?" this is what good looks like:
✅ - Yes
❌ - I'm ok
❌ - Oui
❌ - I'm alright
❌ - Piss off
❌ - Teapot
Whereas in the non-deterministic present we have…
✅ - Yes
✅ - I'm ok
✅ - Oui
✅ - I'm alright
❓ - Piss off
❌ - Teapot
That’s the Oracle Problem. And that’s just one failure mode. We also have:
Hallucinations
Drift
Compound error
Sycophancy
Evaluation-aware behaviour
Unsafe defaults
All of that adds up to…
Tons more output. Tons more code. Tons more ways things can go wrong.
That’s what I’m calling the Code Tsunami 🌊 . We need to rethink and adapt the way we think about and implement quality. Significantly.
…Kinda...
That’s what I was seeing in my own work. Then I started reading.
Things I’ve discovered
How much uncertainty are we willing to tolerate?
I think this is the year we get back to the fundamentals, as explained twice by Angie Jones.

While it’s true that working with AI requires us to adapt, when you consider the full stack, it’s less true. Angie talked about this in her article Testing Pyramids for Agents, where she talked about 4 layers of “uncertainty tolerance”:
Base Layer: Deterministic Foundations. “If this layer is flaky, we know it’s a problem with our software and no AI”
Middle Layer: Reproducible Reality. Use record and playback for “…testing our code’s behaviour given some reasonable model output…”
Upper Layer: Probabilistic Performance. Use benchmarks and aggregates to monitor regression. “A single run tells us almost nothing, but patterns tell us everything.”
Top Layer: Vibes and Judgement. Formalise judgement using rubrics and LLMs. “…turn subjective quality into something we can track and discuss”
I love this framing because it takes the observation “these systems are non-deterministic” and makes it actionable. In those areas where we can’t tolerate uncertainty, we might be able to leverage our unit testing skills to our advantage.
We know how to do that already, right?
…Right!?
Open source done right
The second clue I got from Angie is when she talked about the struggles of open source maintainers facing off against the Code Tsunami.
Agents and humans + coding assistants are churning out pull request (PR) after pull request. Many maintainers reacted by pulling up the metaphorical drawbridge, taking the “open” out of “open source” along with it.
So Angie came through with some timely reminders:
Tell humans how to use AI on your project
Tell the agents how to work on your project
Use AI to review AI
Have good tests
Automate the boring gatekeeping with CI
It was 4 and 5 that caught my attention.
In those two points, she refers to things like solid test suites, linting, type checking, and GitHub Actions. Which should be familiar to us all by now, right?
…Right!?
Harness Engineering
We’ve had Prompt Engineering, Context Engineering, and now Harness Engineering.
This was fascinating. It describes an experiment the team at OpenAI ran where they built and shipped an internal beta that contained “…0 lines of manually-written code.“ 🤯
So what were the engineers doing all day? A different kind of engineering work “…focused on systems, scaffolding, and leverage.“ The agents averaged “3.5 PRs per engineer day”. That compares with 0.6 PRs per day for human-written code.
Of course, the inevitable happened…
As code throughput increased, our bottleneck became human QA capacity.
The tsunami strikes again!

In their own words, the scarce resource was “…human time and attention…” and they got themselves out of it by making application UI, logs, app metrics legible to the agent and creating skills for DOM snapshots, screenshots, and navigation.

It’s a very interesting and very impressive case study. They clearly care a lot about internal quality and maintainability
But that leaves quite a big gap.
Inner Loops, Outer Loops, and Testing in Production
Birgitta Böckeler’s commentary on Harness Engineering first mentioned the gap:
All of the described measures focus on increasing long-term internal quality and maintainability. What I am missing in the write-up is verification of functionality and behaviour.
“Verification of functionality and behaviour” eh? Hmmm… Now that sounds like familiar work!
Vidhya Ranganathan’s excellent post picked up the baton and sent me down a rabbit hole of loops, gaps, and testing in production.
She describes two loops, inner and outer.
The inner loop operates at the code and repository levels and answers the question Does this code conform to our constraints and pass the checks we’ve defined?. The outer loop operates at the system and production level and answers the question does this code actually work correctly for real users, under real conditions we couldn’t fully predict?
The speed at which the inner loop operates and the volume of code it produces necessitates work at the outer loop because that’s where things break for our users. Typically, most teams use pre-production environments to do that testing.
The trouble is, those environments are far too vanilla and pale in comparison to production. The data is too clean/normal, the scale of traffic is tiny in comparison, the horsepower isn’t much reduced, etc etc etc.
Or as I like to put it: Production is where the really weird shit happens.
Historically, testing in production gives people palpitations! But this is where Cindy Sridharan comes in clutch with an excellent model and sound advice on how to do it well.
Testing in Production
Cindy’s core argument is two-fold:
Pre-production verification is necessary but insufficient to cover all risks and failure modes
Testing in Production covers three distinct phases
Deployment
Release
Post-release
And they each have their own specific practices
Deployment. Installing the new software in the actual production environment without exposing it to production traffic. Testing looks like integration tests, load tests, tap compare, and shadowing.
Release. The process of moving production traffic to the newly deployed code. Testing looks like anarying, traffic shaping, feature flagging, monitoring
Post-Release. Monitoring the behaviour of your application and debugging/investigating when the inevitable weird shit happens (my words, not Cindy’s! 😊). Testing looks like teeing, A/B tests, logging/events, monitoring, distributed tracing, chaos testing, metrics
Back to the Outer Loop
Testing production isn’t new, so what makes this so important all of a sudden?
According to Ranganathan, it’s a triple threat of: the inner loops’ testing scope + blast radius + grey failures.
The inner-loop testing scope sounds like testing vs checking.
Blast radius sounds like the tsunami rearing its ugly head again!
The grey failures sound the most interesting to me. A category of failure that sneaks up on you, slowly, like a tiger in the long grass, then BOOM! It necessitates Testing in Production because, by its nature, the problem won’t manifest itself in preproduction environments.
Putting it all together
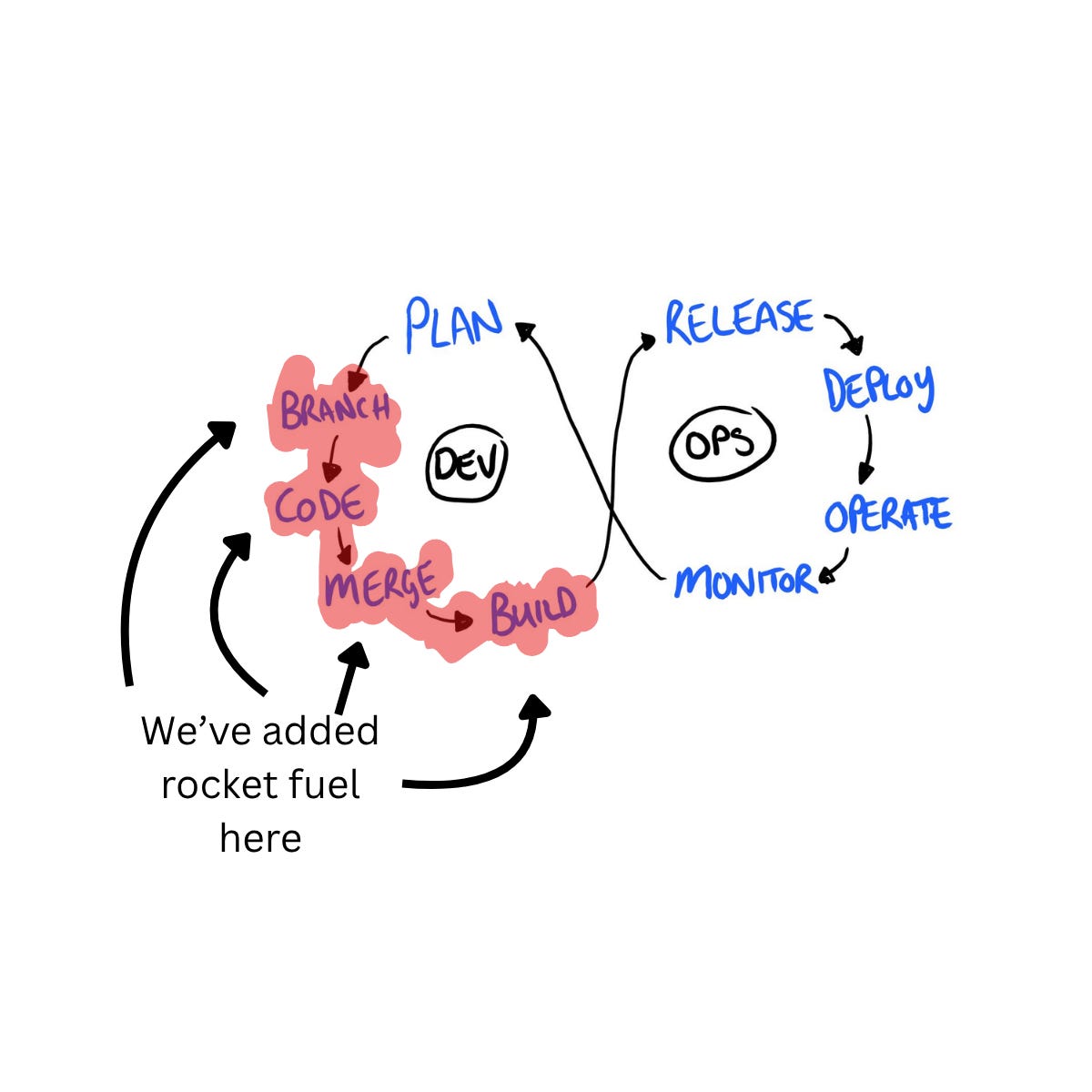
The testing landscape definitely looks different.
Our tools, products, and services are laced with Gen AI, so we need to keep what works and innovate where we have gaps. Luckily for me, that doesn’t mean I need to throw all the experience I’ve earned over the past 20+ years into the trash 😅
The foundations of my testing philosophy are still valid, but I need to deploy them differently.
Things I can take with me
Some familiar themes keep popping up in the things I’m reading.
Risk-based thinking, test strategy, checking vs testing, systems thinking, understanding production issues, and our users are still as relevant as ever.
Good times! Some of the experience from the past 20+ years is still useful 😊
Where can I contribute and have a real impact
Three things spring to mind. One boring. One is somewhat obvious. One a rediscovery.
The Boring One: Task Analysis
This may not be sexy, but it’s powerful.
If my teammates and I can’t articulate what we do clearly enough, anything we try to do with AI will be useless. So this isn’t an AI skill. It’s a thinking skill. And it scales beyond my team to the whole business because every department could be about to hit the same wall.
That’s something I help the team learn and apply.
The Somewhat Obvious One: The Outer Loop
Having doused the code generation part of the SDLC in rocket fuel, now what?
We’ve sort of neglected to do the same for the part of the process where we find out if it works. If production is where the weird and problematic stuff happens, somebody has to design & build the feedback loops, the observability, the tools that help answer the question “What does good look like for real users and how would we know if that’s happening or not?”.
That’s pure unadulterated testing. The new part (for me!) is personally building tools and feedback loops to enable that. I’ll have more to say about that in the next article.
The Things We Forgot We Knew: Tsunami Survival Practices
Good coding and testing practices just became table stakes.
Working in small batches, well-defined pieces of work, CI/CD pipelines, TDD, all of this is now mandatory. Or you drown. That said, while they’re a solid and necessary foundation, they won’t take us the whole way. They buy us the time we need to build the next generation of tooling to help us tolerate uncertainty.
Some practices I need to start learning how to do, based on the reading I’ve done so far, are evals, record and playback (from Angie’s new pyramid), and production behavioural monitoring (drift detection, anomaly flagging, etc). These will help me find those grey failures Ranganathan talked about.
That’s not all folks…
So that’s where I am with the jigsaw.
For the piles at least. I have a much better sense of where I am, where I can help, and how.
Next I’ll tell you about the edges. But that will have to wait until the next article because this one is already quite long ☺️
Thank you for bringing an honest perspective that I concur pretty much 100% with you. Will be sharing this with our testing/quality engineers, and with our AI program leadership (that I'm somehow leading now....lol....try to smile...)
Excellent. Thanks for sharing.